大学、専門学校や企業などの研究室を訪問し、研究テーマや実験の様子をレポート
第28回 Part.3第28回 ビッグデータの新たな解析法を開発(3)
Part.3
情報の転移方法の開発によって
糖尿病の因子や発症確率を探る
汪 金芳(ワン・ジンファン)教授
公開:
数年前から「ビッグデータ」という言葉がよく使われるようになった。このビッグデータの解析や活用のために、「データサイエンス」という新しい学問も登場している。そこで今回は、ビッグデータを解析する新たな手法を研究している横浜市立大学の汪金芳先生の研究室を訪ね、データサイエンスの意義や具体的な研究内容について話を伺った。(Part.3/全4回)
Part.1「データから新しい価値を創造するデータサイエンス」はこちら
Part.2「ビッグデータを活用するために新たな統計解析の方法を開発」はこちら
 ▲汪 金芳 教授
▲汪 金芳 教授
ベイズの定理をもとにしたベイズ推論は、ビッグデータの研究と活用に有効だが、何らかのオリジナルデータに、別のビッグデータの情報を取り込めるようにするという難しい課題があるそうだ。
汪先生は、その課題をクリアするため、糖尿病の発症要因や発症確率をテーマにして、新たな統計解析法の開発に取り組んだ。
これは、糖尿病などを専門とする、ほさか内科医院(東京都江戸川区)の保坂成俊医師との共同研究。
「この研究の主目的は、従来の回帰分析の手法を拡張し、1つのビッグデータから得られる情報を、もう1つの詳細なデータに転移させる方法を開発することです。ただ、方法論の開発だけではなく、糖尿病の診断や予防に役立てていただくことをメインの目的にしています。
というのも、糖尿病の診断では、血糖値が126を超えたら糖尿病だという従前からの基準があります。しかし、血糖値は測定の時間などによってバラつきがあり、測定機器の限界もあり、1回・2回の測定値の平均で126というラインを超えるか超えないかだけで判断することには現場の医師から疑問の声もあがっているのです。
とくに糖尿病を専門とする医師は、糖尿病の有無の診断だけでなく、性別、年齢、肥満度などいろいろな要因から糖尿病になる確率を知りたいという要望もあります。そこで、糖尿病を具体的な健診データに基づいて研究することにしたのです」
実際の患者ごとの詳細なデータに
厚生労働省などのデータを取り込む
背景情報として用いたのは、ある総合病院の健康診断のデータだ。これは、患者さんごとに「HbA1c(ヘモグロビンA1c)」「血糖値」「性別」「年齢」「身長」「体重」「家族歴」「善玉コレステロール」「中性脂肪」「アルコール」「睡眠」など多岐にわたる因子を調べたもの。
「実際には、因子の項目は百数十個あります。すべての患者さんについてこれらの項目すべてが揃っているわけではありませんが、年齢も性別も異なる数多くの患者さんから得られた非常に詳細なデータです。
一方で、厚生労働省が毎年行っている『国民健康・栄養調査』というものがあり、ヘモグロビンA1cの数値を年代別にまとめたデータがあります。たとえば、ある年の調査では、6.60%~6.70%は20代は0、30代も0、40代は13人といった結果が出ています。ちなみに、6.5%以上になると糖尿病の疑いとされています。
これ以外にも、糖尿病に関連するさまざまな政府調査データがあり、それらのデータをベイズ統計学でいう『事前情報』として、健診データなどに取り込んで、糖尿病の発症因子の影響度や発症確率をより正確に予測することに取り組んだのです」
ベイズ推論を応用した解析で
情報の転移と統合を実現
この研究の主目的であり、難しい課題でもあったのが、オリジナルデータに、明らかにデータとしての形式が異なる厚生労働省などのデータを事前情報としてどのようにして転移し統合させるかということだった。そのために活用したのがベイズの定理によるベイズ推論だ。
厚生労働省などの背景データを、タテ軸(行)が年齢でヨコ軸(列)が因子の表にすると、たとえば、「何歳の人のヘモグロビンA1cの数値」という1つずつのセルができる。そのセルごとに、予測モデルを立ててベイズの定理を用いて計算し、セルの数値と最も整合するように予測モデルのパラメータ(母数)を推測したそうだ。
「セルごとに積分の計算をするのですが、これはスペルチェックよりもはるかに難しく、人間の手では膨大な時間がかかるので、コンピュータのパワーで計算しました。そのうえで、各因子が糖尿病の発症にどの程度の影響をおよぼしているかという係数を求め、さらに、男女別、年齢別に糖尿病の発症確率の予測もしました」
汪先生は、グラフを示しながら説明をしてくださった(下図参照)。
「これは、ベイズ的な観点からの糖尿病発症予測確率のグラフです。赤が男性で、実線はオリジナルデータに厚生労働省などのデータを統合したもの、点線は統合していないものです。下にある2本が女性です。男性のほうが、確率が高くなるということです。女性のうち青はデータを統合したもの、緑は統合していないものです。
男女とも、事前情報としての厚生労働省などのデータを統合したほうがやや低めに出ています。ベイズ推論によれば、低めに下方修正されたもののほうがより信憑性があるのではないかと考えられます」
このようなデータの転移によって、より正確な確率などを求めていくことが、データサイエンスの世界では非常に重要になっているのだという。
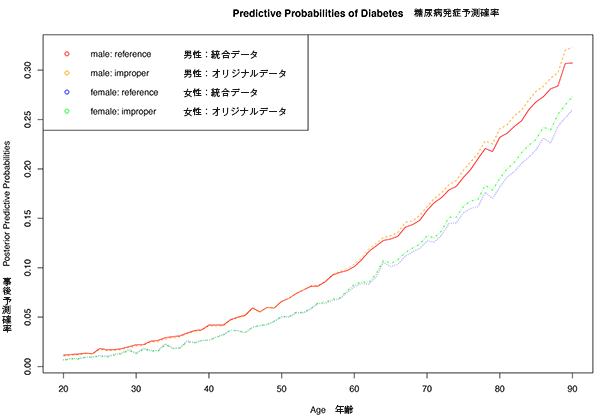 ▲糖尿病発症予測確率
▲糖尿病発症予測確率オレンジの点線は男性で、オリジナルデータによるもの。赤の実線は男性で、厚生労働省などのデータを統合したもの。緑の点線は女性で、オリジナルデータによるもの。青の点線は女性で、厚生労働省などのデータを統合したもの。※図中の日本語表記は編集部による
《つづく》
●次回は、Part.4『科学の大きな転換期を迎えデータで世界に迫る』です(5/11公開予定)