大学、専門学校や企業などの研究室を訪問し、研究テーマや実験の様子をレポート
第28回 Part.2第28回 ビッグデータの新たな解析法を開発(2)
Part.2
ビッグデータを活用するために
新たな統計解析の方法を開発
汪 金芳(ワン・ジンファン)教授
公開:
数年前から「ビッグデータ」という言葉がよく使われるようになった。このビッグデータの解析や活用のために、「データサイエンス」という新しい学問も登場している。そこで今回は、ビッグデータを解析する新たな手法を研究している横浜市立大学の汪金芳先生の研究室を訪ね、データサイエンスの意義や具体的な研究内容について話を伺った。(Part.2/全4回)
Part.1「データから新しい価値を創造するデータサイエンス」はこちら
 ▲汪 金芳 教授
▲汪 金芳 教授
汪先生は、ビッグデータの統計解析によって、これまで扱えなかったようなデータを社会に役立てていくための方法などを研究している。
より具体的には、ビッグデータをどのように解析すればいいのか、オリジナルの詳細なデータなどにビッグデータを取り込んでいくにはどうすればいいのか、といったテーマに取り組んでいるそうだ。
その方法論の中心になっているのが「ベイズ統計学」。これはいま、ビッグデータや人工知能などの研究において、非常に重要になってきているものだという。そこで、ビッグデータ時代の統計解析について、ベイズ統計学を中心に教えていただくことにした。
「かつては、何らかのテーマについて、その確率や可能性を探るため、研究者が仮説を立て、それに基づいてデータを収集し、解析するということをしていました。これは現在でも行われています。
しかし、ビッグデータの時代になると、データが先にあるという現象も起こります。たとえば、ツイッター上に頻繁に出てくる何かの情報があるとします。
その情報から実世界について1つの仮説を立てる。その仮説はデータに基づく検証が必要なので、数理モデルを立てたりシミュレーションをしたり、専門家の意見を聞くなど、あらゆる手段で検証しながら、仮説が正しいか探求していきます。このように、統計科学のあり方が大きく変わってきているのです」
オリジナルデータの解析に
ビッグデータの情報を取り込む
こうした統計科学の変化のなかで、汪先生は、オリジナルに取得したデータにビッグデータから得られる情報を取り込んで、より精度の高い推論にしていく方法の確立をめざしている。
「アメリカで使われていて、統計科学の世界では標準的になりつつある言葉に『リアルワールドデータ』というものがあります。目の前にある、実世界から取得したデータという意味です。このリアルワールドデータから、ベイズ統計学では『事前情報』と呼ばれるものを抽出し、より詳細なオリジナルデータに埋め込み『新しい客観的ベイズ推論』を構築します。
ベイズ推論は、事前情報に新しい情報を加えることによって『事後情報』として更新されます。この事後情報は通常は確率分布として表現されます」
人工知能の研究でも使われる
ベイズ推論
ベイズ推論は、起こった事象からその原因を推定することができるため、人工知能の研究でも積極的に使われているもので、その根底には「ベイズの定理」がある。
汪先生は、ベイズの定理について、英単語を入力した場合のスペルチェックを例にして説明してくださった。
「入力した単語が意図した単語であるか調べるスペルチェックの場合、事前情報としては、候補となるそれぞれの単語が出現する頻度があります。
入力が間違っているか間違っていないかにかかわらず、これが最もよく出てくる単語、これが次によく出てくる単語というように、それぞれの単語の頻度があるのです。この頻度を求めるには、何らかのデータベースを使うことになります。100億個の単語のなかでこの単語は何回出たかといったかたちで頻度を求めます。これは『言語モデル』と呼ばれるものに基づいて求めます」
次に、ある単語が入力された場合、たとえば「lates」(図参照)と入力された場合、それが、候補となる何らかの単語を入力しようとしたものである確率がどのぐらいあるかを調べる。
これは『条件付き確率』と呼ばれるが、候補となる単語を当てる確率なので、統計学では『事後確率』と呼ばれる。この『事後確率』の計算がいまの目的となる。そのために、データベースに基づいて、候補となる単語を意図した場合、いまと同じ入力がされた『誤差モデル』に基づく条件付き確率の仮定を必要とする。
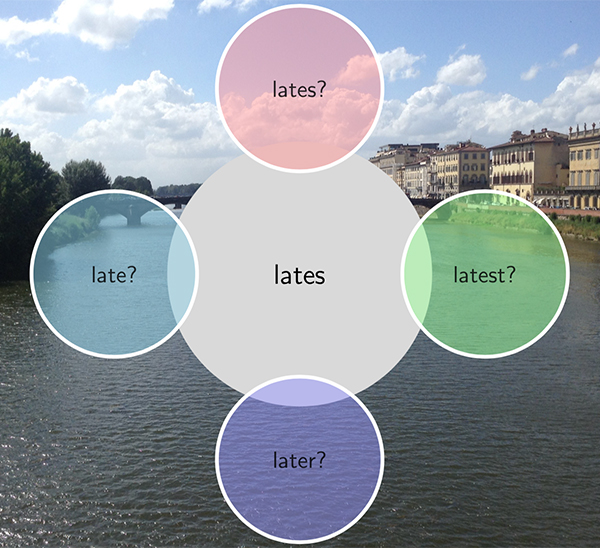 ▲入力した単語と候補になる単語のイメージ
▲入力した単語と候補になる単語のイメージ「入力した単語の候補となる単語、たとえば『lates』『late』『later』『latest』などの事後確率を求めるために『ベイズの定理』を使います。このベイズの定理によって、候補になる単語ごとに条件付き確率が計算され、確率の高いものを入力した人に提示することができるのです」
膨大なデータから候補を選び、その候補も場合によっては数百にもおよぶこともあるため、コンピュータには高いパワーが不可欠になる。
新しい情報を加えるごとに
精度を高めることが可能
ベイズの定理によって推定された数値、つまり事後確率は、新しい情報が得られ、それによって計算し直すごとに更新され、精度を高めていくという特徴がある。これは、人間の思考パターンに類似する部分もある。ベイズ推論がビッグデータや人工知能などの研究で重要な役割を担っているのも、こうした特徴、利点があるからだ。
汪先生は、このベイズ推論を応用して新たなデータ解析法の研究を進めている。
「ベイズ推論の本質は、情報を積極的に使うことにあります。たとえば、何らかのデータから関心のある事象の確率や可能性などを探る場合に、そのデータだけでなく、別のソースから得られるデータも積極的に使う。データに聞く、データに教えてもらう、『データ中心型思考』ということですね」
《つづく》