大学、専門学校や企業などの研究室を訪問し、研究テーマや実験の様子をレポート
第22回 Part.2第22回 アクティブラーニング支援技術を研究(2)
Part.2
自然言語処理の技術を使って、
発言内容を解析・分類する
情報理工学科 田村 恭久教授
公開:
更新:
ここ数年、学校教育のなかで「アクティブラーニング」が大きなキーワードの1つになっている。アクティブラーニングは、大学教育改革の流れのなかで注目されるようになり、各大学においてさまざまな取り組みが始まっている。また、中学校や高等学校で導入するケースもあり、もともと「調べ学習」などアクティブラーニング的な要素のある小学校にも波及しようとしている。学問の世界でも、アクティブラーニングの方法論はもちろん、アクティブラーニングをコンピュータで支援する研究などが始まっている。そこで今回は、上智大学理工学部情報工学科の田村恭久先生の研究室を訪ね、アクティブラーニング支援技術の研究について話を伺うことにした。(Part.2/全4回)
自然言語処理の技術を使って
発言内容を分解・再構築
 ▲田村 恭久教授
▲田村 恭久教授
ここ数年、学校教育のなかで「アクティブラーニング」が大きなキーワードの1つになっている。アクティブラーニングは、大学教育改革の流れのなかで注目されるようになり、各大学においてさまざまな取り組みが始まっている。
今回は、上智大学理工学部情報工学科の田村恭久先生の研究室を訪ね、アクティブラーニング支援技術の研究について話を伺う。
ここからは、研究室で取り組んでいる個別の研究テーマについて教えていただくことにしよう。
研究室では、コンピュータによる本格的な協調学習支援を可能にしていくために、コンピュータで協調学習の議論内容を解析し、その結果を踏まえて議論に自動介入する研究に取り組んでいるという。その議論内容の解析とはどのようなものなのだろうか。
「協調学習を支援していくには、ディスカッションでどういうことを話しているかコンピュータが認識することが必要になってきます。そのために用いているのが、先ほどお話しした自然言語処理という技術です。
現在の自然言語処理では、人間の発言(言葉)を一旦、単語(品詞)ごとにバラバラにします。たとえば「私」「は」「スイカ」「が」「好き」「です」というように。そのうえで、「私は」「スイカが」「好きです」と『節』に組み上げ、さらに『文』に構成していきます。この技術は主に言語学者の方が研究していて、いまでは精度の高いソフトがつくられています」
単語や文のマッチングで
発言の類似度を探る
この自然言語処理の技術を応用して、研究室では、議論内容を解析する実験を行いながら研究を進めている。
実験は、学生のモニターを集めたり、田村先生の授業で学生に協力してもらって行っている。このとき、学生はノートPCかタブレットPCを使用し、それは教員側のメインPCに接続されていて、協調学習のグループディスカッションをPCも使いながら行うというしくみだ。
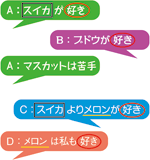
「たとえば、Aさん、Bさん、Cさん、Dさんの4人で議論する場合、誰の発言(入力された文章)かということをメインPCは認識します。そして、自然言語処理によって単語に分解し、Aさんの発言に含まれる単語(名詞)とほかの人の発言に含まれる単語(名詞)がどれくらい一致しているかを統計的に処理して解析します。そうすることで、それぞれの人の発言の類似度がわかるようになります。
身近な例で言うと、PCや携帯電話から検索サーバを使って何らかの言葉を検索すると、その言葉を含むWebページがズラッと表示されますね。基本的にはそれと同じような、言葉のマッチングの技術を使っているのです」
同音異義語も認識できるオントロジー
ただ、日本語は、同じ単語でも少し違う意味で使われたり、別の単語でも同じ意味で使われるケースもある。
「同じ内容を別の言葉で言い換えた場合、そのまま解析すると、本来は同じ意味なのに違う言葉として認識されてしまいます。これを解消するものとして、オントロジーと呼ばれる技術があります。これはわかりやすく言うと類義語辞典のようなものです。これとこれは同じような意味なんだよという単語のグループをつくっているのです。
ある単語がAさんの発言に出てきた。別の単語がBさんの発言に出てきた。それは単語としては別のものだけれど、オントロジーでチェックすると、実は同じ意味を持っているということがわかるのです。そうすると、Aさんの発言とBさんの発言は似た内容だと認識できるわけです」
次に問題になってくるのは、発言内容がどういう意味を持っているのかということだ。
「言葉レベルでは類似度がわかるようになったとすると、発言内容が賛成意見なのか反対意見なのか、あるいは質問なのかという『意味』を知りたくなりますね。 ところが、『意味』をコンピュータで自動的に解析することは現状ではできません。これを可能にするには相当時間がかかると思います。いまの高校生や大学生の方々に、研究を重ねて解決していっていただきたい大きな課題ですね」
より精度の高い解析には
外部のサーバを活用
発言の類似度の解析は単語(名詞)のマッチングによって行うだけではない。単語を『節』や『文』に組み上げて、その組み合わせでマッチングする方法もあるのだという。この場合、より正確なマッチングをするために外部(Yahoo)の解析サーバを利用することもあるそうだ。
「発言内容を単語に分解することも、『節』や『文』に再構築することもメインPCで実行可能です。
しかし、Yahooの解析サーバは、この再構築に際して、幅広く収集した日本語文の構造と、解析対象の文を照らし合わせ、より正確な構造を再構築する機能を併せ持っています。このため、Yahooのサーバを利用すると、より精度の高い再構築が可能になるのです」
Yahooの解析サーバへの発言データの送信、結果の受信、それを基にした発言の類似度の統計的処理は、メインPCが自動的に行うことができるようになっている。
《つづく》
●第3回は『コンピュータによる、議論への自動介入のしくみについて』についてです。